I have unlocked my phone with my face probably thousands of times. Never have I ever once thought about it. Then, a few weeks ago, I sat in a lecture about something called eigenfaces. And now I cannot stop thinking about my phone.
What even is a face, mathematically speaking?
Before anything else, there are a few questions worth considering. When your phone looks at your face, what is it actually seeing? What is a face, as far as a computer is concerned?
Take a greyscale photograph of a face. Every pixel is just a number, a brightness value between 0 and 255. A 100 x 100 image is then 10,000 numbers written one after another. That list of numbers is a vector. And a vector with 10,000 entries is, geometrically, just a point in a 10,000 dimensional space.
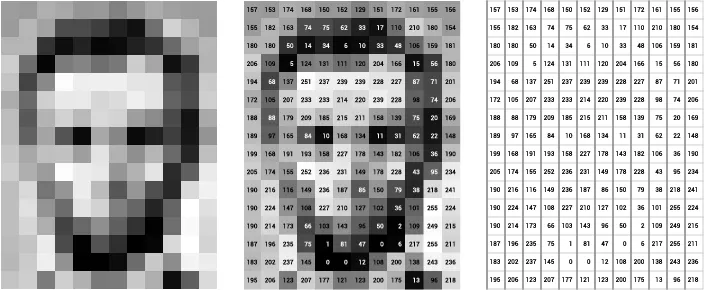
Every face you’ve ever seen is a single point floating somewhere in that vast space. Your face is a point, your passport photo is a point, even the slightly unflattering one from your student ID card is also a point, however much you might wish otherwise.
When I first thought about this, I couldn’t help but wonder if faces scatter randomly across that space or follow some kind of structure.
It turns out there is structure. Faces look like faces, not like static or noise or a photograph of a forest. The region of high dimensional space actually occupied by face images is a small, organised corner. And if we know the shape of that corner, we can describe any face very efficiently, using far fewer than 10,000 numbers.
But how do we find that corner?
The 1991 paper with a surprisingly good title
In 1991, two researchers at MIT, Matthew Turk and Alex Pentland, asked exactly that question. Their answer was a paper called Eigenfaces for Recognition1, widely considered the first working facial recognition system.
I find it genuinely amazing that this was 1991. No iPhone, no neural engine, no TrueDepth camera. Someone looked at a pile of photographs and bet linear algebra could solve this.
Their approach is called Principal Component Analysis (PCA). Say we have thousands of face images, each one a point in a 10,000 dimensional space, and we need to find the directions in that space where faces actually vary. Meaningful directions with axes that capture what actually differs between faces.
To find them, we first compute the average face, and subtract it from each image to isolate the variation. Then we build a covariance matrix, which is a way of measuring how pixel values vary together across all our images. If pixel A tends to be bright whenever pixel B is bright, the covariance matrix captures that relationship. It’s essentially a map of the hidden correlations in our data.
The directions of greatest spread turn out to be the eigenvectors of that covariance matrix. And those eigenvectors of the face data are the eigenfaces.
Why eigenvectors, and not something else?
If you’ve ever met eigenvectors2 in a lecture, you probably encountered them as the vectors that don’t change direction when a matrix is applied to them. Which is true, and also sounds slightly like a description of someone very stubborn at a meeting.
When we apply a transformation to most vectors, two things happen at once. The vector gets scaled (stretched or squished), and it gets rotated into a new direction. Eigenvectors are the special directions where the rotation part doesn’t happen. Only the scaling, and the amount of scaling is the eigenvalue.
For the covariance matrix of a dataset, the eigenvectors with the largest eigenvalues point in the directions of greatest variance, or the axes where the data spreads out the most. In the context of face images, those are the directions capturing the most meaningful variation between faces.

Eigenfaces look a bit unsettling3. They don’t resemble any particular person, and look more like the concept of a face, distilled and slightly haunted. But the useful thing is that any actual face can be written as a weighted combination of eigenfaces. A bit of eigenface 1, some eigenface 2, very little of eigenface 7. Those weights become a compact coordinate for that face in what Turk and Pentland called face space.
So instead of storing 10,000 numbers per face, we keep maybe 50 to 100 eigenfaces and represent every face as 50 to 100 weights. Recognition becomes a question of distance, of how close two faces’ coordinates are in face space. Near neighbours are the same person, far apart means different people.
I think the beauty here is the compression. We started with an intractable amount of information, found the directions that matter most, and discarded everything else.
A brief note on how you actually compute any of this
The covariance matrix of face data is enormous, and directly computing its eigenvectors would be, for realistic image sizes, computationally catastrophic. This is where SVD (singular value decomposition) earns its place.
Instead of decomposing the huge D×D covariance matrix directly, Turk and Pentland worked with a much smaller M×M matrix, where M is the number of training images, not the number of pixels, and recovered the eigenfaces from that. SVD allows us to rewrite any linear transformation as a rotation, then a scaling along principal axes, then another rotation. The eigenfaces are those principal axes for face data, which means we can decompose any matrix into a product of three simpler ones.
Would this actually work with glasses?
I was fairly satisfied with all of this, until I remembered why I started looking in the first place. I was wearing my glasses the day I walked out of that lecture. I don’t always wear them, and I remember standing wondering how my phone knew it’s still me.
The problem with eigenfaces is that it operates on flat 2D photographs. Flat photographs are easy to fool, print someone’s face, hold it up to the camera, done. They also struggle badly with different lighting, a different expression, or a pair of glasses. Apple needed something a photograph couldn’t defeat.
Eigenfaces, beautiful as they are, cannot be the full story. So what is Apple actually doing?
How Apple solved it

Face ID, introduced with the iPhone X in 2017, works in three dimensions. When you glance at your phone, the TrueDepth camera fires more than 30,000 invisible infrared dots onto your face. Those dots land differently depending on your actual geometry. Your nose pushes some forward, your eye sockets pull others back. An infrared camera reads the distorted pattern and reconstructs a depth map, or a precise 3D model of your face’s geometry in milliseconds.
That depth map, alongside a 2D infrared image, goes to the neural engine on Apple’s chip. Then, a neural network transforms all of this into a compact mathematical representation of your face. This is nothing but a string of numbers, stored encrypted on your device, never sent to Apple, never backed up to iCloud4.
When you unlock your phone, the same process runs again. The two representations are compared. If they are close enough, in exactly the same sense that nearby points in face space are the same person, you’re in. So the probability that a random stranger could pass this check is less than one in a million.
And the glasses? The depth map reads your bone structure, not your pixels. The geometry of your face doesn’t change when you put them on.
Point Taken
Eigenfaces and Face ID are not the same thing. But they are asking the same question, namely of how do you represent a face efficiently as a mathematical object?
Eigenfaces answered it with eigenvectors, dimensionality reduction, and a low dimensional subspace that captures the structure of human faces. Face ID answers it with 3D geometry and neural networks. The tools evolved enormously in thirty years. But the intuition that a face is a point in a space, and what matters is where that point sits relative to others, remains.
I stood outside that lecture wondering how my phone knew it was me. Never had I thought that the answer would start with a covariance matrix and a very sensible question about which directions matter most, or that it was worked out in 1991 by two people at MIT who probably weren’t thinking about iPhones, because iPhones didn’t exist5.

- The full paper is freely available online and can be found here ↩︎
- If you want one of the best intuition for eigenvectors, 3b1b’s Essence of Linear Algebra series is the place to start ↩︎
- There is also something philosophically unsettling about the average face. It is somehow nobody and statistically, everybody… and I have been thinking about this for longer than is probably healthy. ↩︎
- I really think this detail about Apple storing a mathematical representation rather than an image of our faces is one of the reassuring things about Face ID. ↩︎
- That’s why I love Maths, it has a habit of showing up with the answer before anyone’s thought of the question ↩︎
