I often find it hard to come up with ideas for things, and that probably shows in the spontaneous nature of both the topics and timing of my posts.
More often than not, my ideas for posts come from conversations. Earlier this week, I had a fascinating conversation with my tutor about the beauty of Shor’s algorithm and its use of Fourier analysis1. Those words might not mean much unless you’ve come across them before, but that conversation did get me thinking. When learning something new, it’s surprisingly easy for the beauty of an idea to get buried under the notation used to describe it.
To be honest, I’ve been feeling this lately in lectures. Sometimes you find yourself just sat there, copying down lines of equations as they appear on the board, trying to keep up, trying to not to fall behind, and somewhere in all of that, the idea itself just… disappears. Surely I can’t be the only one who’s felt that while calculating yet another partial derivative.
And to be clear, the equations aren’t the problem. They matter, they give things precision, they’re what let us actually do the maths. But sometimes it feels like they take over.
It becomes less about understanding what’s going on, and more about getting through the steps. You follow the method and arrive at the answer, but somewhere along the way, the reason those steps exist in the first place gets lost.
Which is a shame, because underneath all of that, there’s usually something genuinely beautiful going on. With that in mind, here’s my attempt at explaining something I’ve been learning recently2 in one of my modules with as little mathematical jargon as possible.
Lunch of a Foggy Hike
Imagine you’re hiking on a mountain. At first, everything’s clear, you can see the path ahead, the slope of the land, maybe even the bottom in the distance. But then out of nowhere, a thick fog rolls in.
Within minutes, visibility drops to almost nothing. You can’t see more than a few steps in front of you. The path is gone and now it’s just you, the ground beneath your feet, and a lot of uncertainty.
To make things worse, you remember something slightly unfortunate: you left your lunch in the car, which happens to be the bottom of the mountain.
And now you’re hungry, very hungry. So suddenly, this isn’t just a casual hike anymore, you’ve got a very important mission, namely to get to the bottom of the mountain and have the best lunch of your life.
However, there’s a slight problem. You don’t have an OS map, no clear path in sight, and no idea where the bottom of the mountain actually is. All you can do is look around you and where you’re standing. So what do you do to get to your lunch?
You pause for a second and look around as much as you can in the fog. You can’t see far, but you can feel the ground beneath your feet.
So you decide take a small step in one direction. It feels like you’re going slightly downhill. You try another direction, but this time it feels flatter. Another step feels slightly uphill, so definitely not that one. So you continue to pick the direction that feels like it goes downhill the most, and take a step in that direction.
It’s quite literally a case of taking things one step at a time. You don’t actually need to know where the bottom is, all you need to know is from where you am right now, which way goes down the most?
And if you keep doing that, with some care and patience, you’ll make progress, and with some luck, might even get to your lunch before your dinner time!
Return of the Notation
What we’ve been doing this whole time is essentially trying to get to the “best” position which in our case, is the bottom of the mountain.
But instead of seeing the whole picture, we’re making decisions based only on what’s happening locally, right where we are. And at every step, we ask the same question: Which direction from here takes me downhill the fastest?
And then we move a little bit in that direction.
In computational maths, the problems often look a bit different, but the goal is very similar. Instead of a mountain, you might have a function, i.e. a way of assigning a value to every point. And instead of trying to get to the bottom of a hill, you’re trying to find the input that gives you the smallest possible value.
Earlier, I was complaining about how equations can hide the beauty of an idea. The equation doesn’t mention fog, or the mountains, or lunch, and it doesn’t need to. All of that information has been distilled into something precise and powerful, something mathematicians can apply in spaces we can’t even picture. But once you understand what’s going on, every part of of the equation starts to feel like it’s telling a story.
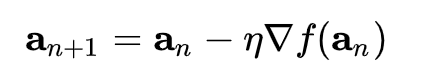
At first glance, the above just looks like a bunch of symbols, but now we can walk3 through each of them in order:
an – think of this as your current position on the mountain
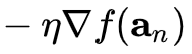
This funny notation above represents the step in gradient or how big of a step we decide to take in the ‘uphill’ direction, i.e. the steepest way things increase from where you are, and we add the minus sign so that we go the opposite way. Too big of a step, and we might overshoot. Too small, and it’ll take forever.
an+1 – this is where you end up after taking that step
Additional Reading/Watching
There is, however, a small catch.
Going downhill doesn’t always guarantee you’ve reached the lowest point possible. Sometimes, you might end up in a dip, a place that looks like the bottom from where you are, but isn’t actually the lowest point on the whole mountain. Formally, these are called local minima.
From your position, every direction goes uphill so you stop. But somewhere else, there might be an even lower point you never reached.
This idea of just taking small steps downhill doesn’t just work on mountains; we can generalise it to work in any number of dimensions.
This is the same concept that sits underneath a huge amount of modern machine learning. Training a neural network to recognise images, generate text, play games is, at its core, just this process repeated over and over again.
Gradient descent is just amazing and insanely powerful, and I promise its applications are far more exciting than potentially hunting for your lunch on a foggy hike. If you want to see this visualised properly (and much better than I can describe it), I’d highly recommend watching 3Blue1Brown video in his series of Deep Learning linked here.
If anyone has any ideas on how to get ideas, feel free to leave a comment below!
- In short, Shor’s algorithm is a method for factoring large prime numbers which is notoriously difficult. So what it does is turns the factoring problem into a finding repeating patterns in square roots using a quantum version of Fourier analysis (QFT). Fourier analysis is just beautiful and I plan to do a post on it in the future, but it essentially lets you break a signal into a combination of sine and cosine waves (or more compactly, just have complex exponentials with imaginary numbers) and extract frequencies from it which in turn help with finding the repeating structure needed to recover factors of an integer. Anyway, I find it fascinating that you can take a problem that looks purely about numbers and somehow the solution can involve waves and frequencies and imaginary numbers, it’s totally not obvious, and yet it works, maths is magic. ↩︎
- As good as it would be to discuss gradient descent in a post, this is also within my personal interest to motivate myself to do revision for my summer exams ↩︎
- pun intended ↩︎
